 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKForge: Program Synthesis for Diverse AI Hardware Accelerators
Nov 17, 2025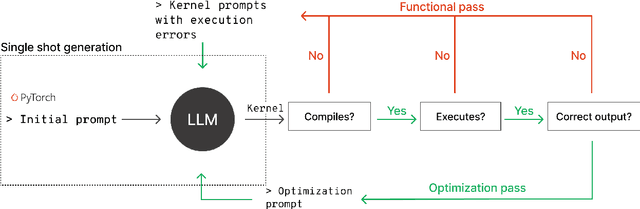

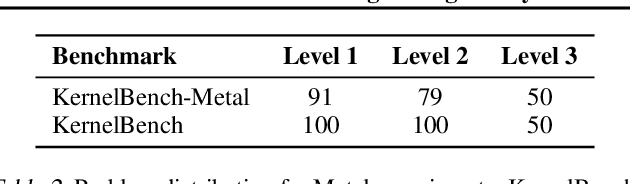
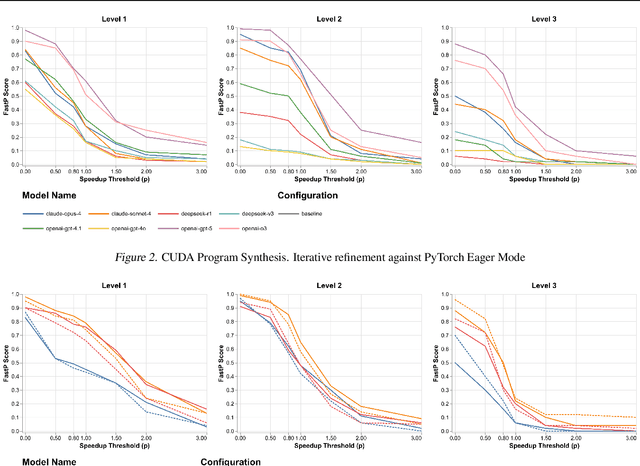
GPU kernels are critical for ML performance but difficult to optimize across diverse accelerators. We present KForge, a platform-agnostic framework built on two collaborative LLM-based agents: a generation agent that produces and iteratively refines programs through compilation and correctness feedback, and a performance analysis agent that interprets profiling data to guide optimization. This agent-based architecture requires only a single-shot example to target new platforms. We make three key contributions: (1) introducing an iterative refinement system where the generation agent and performance analysis agent collaborate through functional and optimization passes, interpreting diverse profiling data (from programmatic APIs to GUI-based tools) to generate actionable recommendations that guide program synthesis for arbitrary accelerators; (2) demonstrating that the generation agent effectively leverages cross-platform knowledge transfer, where a reference implementation from one architecture substantially improves generation quality for different hardware targets; and (3) validating the platform-agnostic nature of our approach by demonstrating effective program synthesis across fundamentally different parallel computing platforms: NVIDIA CUDA and Apple Metal.
MLPerf Automotive
Oct 31, 2025We present MLPerf Automotive, the first standardized public benchmark for evaluating Machine Learning systems that are deployed for AI acceleration in automotive systems. Developed through a collaborative partnership between MLCommons and the Autonomous Vehicle Computing Consortium, this benchmark addresses the need for standardized performance evaluation methodologies in automotive machine learning systems. Existing benchmark suites cannot be utilized for these systems since automotive workloads have unique constraints including safety and real-time processing that distinguish them from the domains that previously introduced benchmarks target. Our benchmarking framework provides latency and accuracy metrics along with evaluation protocols that enable consistent and reproducible performance comparisons across different hardware platforms and software implementations. The first iteration of the benchmark consists of automotive perception tasks in 2D object detection, 2D semantic segmentation, and 3D object detection. We describe the methodology behind the benchmark design including the task selection, reference models, and submission rules. We also discuss the first round of benchmark submissions and the challenges involved in acquiring the datasets and the engineering efforts to develop the reference implementations. Our benchmark code is available at https://github.com/mlcommons/mlperf_automotive.
MLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from μWatts to MWatts for Sustainable AI
Oct 15, 2024



Rapid adoption of machine learning (ML) technologies has led to a surge in power consumption across diverse systems, from tiny IoT devices to massive datacenter clusters. Benchmarking the energy efficiency of these systems is crucial for optimization, but presents novel challenges due to the variety of hardware platforms, workload characteristics, and system-level interactions. This paper introduces MLPerf Power, a comprehensive benchmarking methodology with capabilities to evaluate the energy efficiency of ML systems at power levels ranging from microwatts to megawatts. Developed by a consortium of industry professionals from more than 20 organizations, MLPerf Power establishes rules and best practices to ensure comparability across diverse architectures. We use representative workloads from the MLPerf benchmark suite to collect 1,841 reproducible measurements from 60 systems across the entire range of ML deployment scales. Our analysis reveals trade-offs between performance, complexity, and energy efficiency across this wide range of systems, providing actionable insights for designing optimized ML solutions from the smallest edge devices to the largest cloud infrastructures. This work emphasizes the importance of energy efficiency as a key metric in the evaluation and comparison of the ML system, laying the foundation for future research in this critical area. We discuss the implications for developing sustainable AI solutions and standardizing energy efficiency benchmarking for ML systems.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021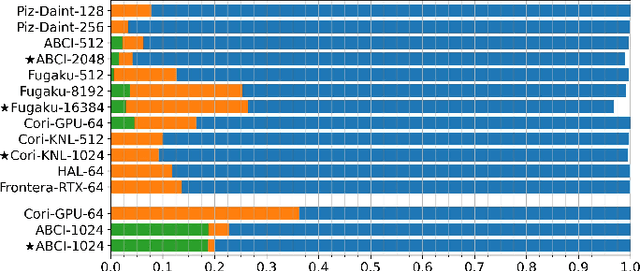
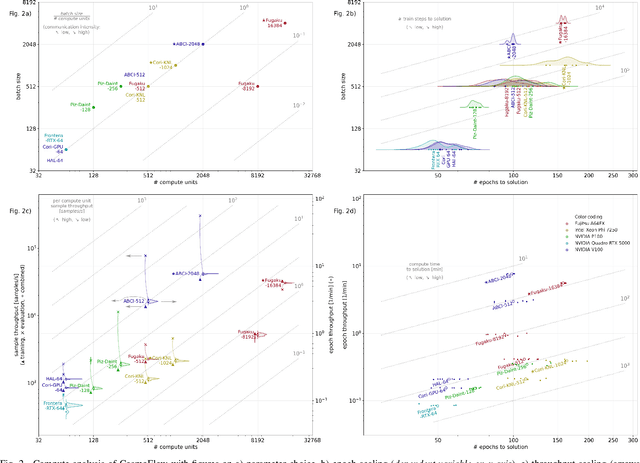
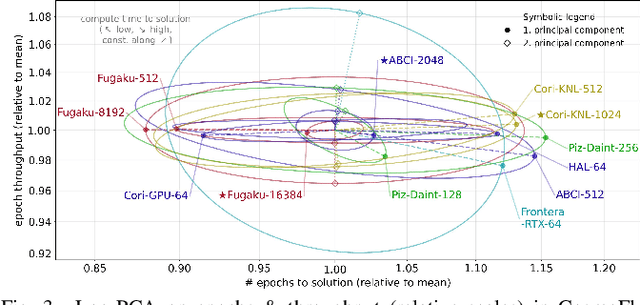
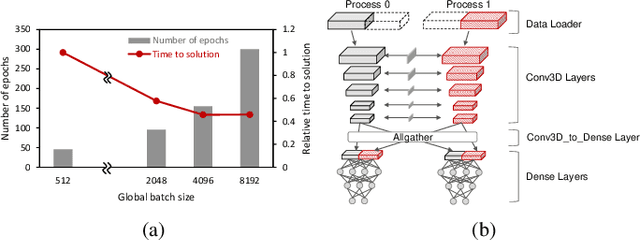
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
MLPerf Inference Benchmark
Nov 06, 2019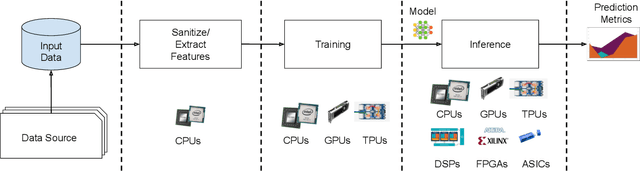
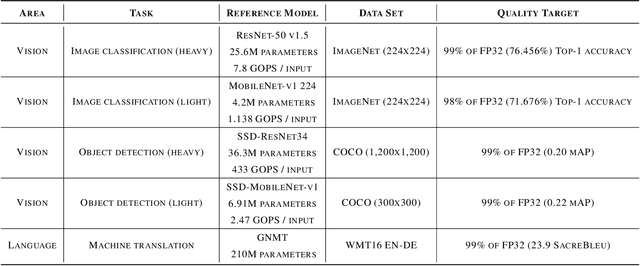
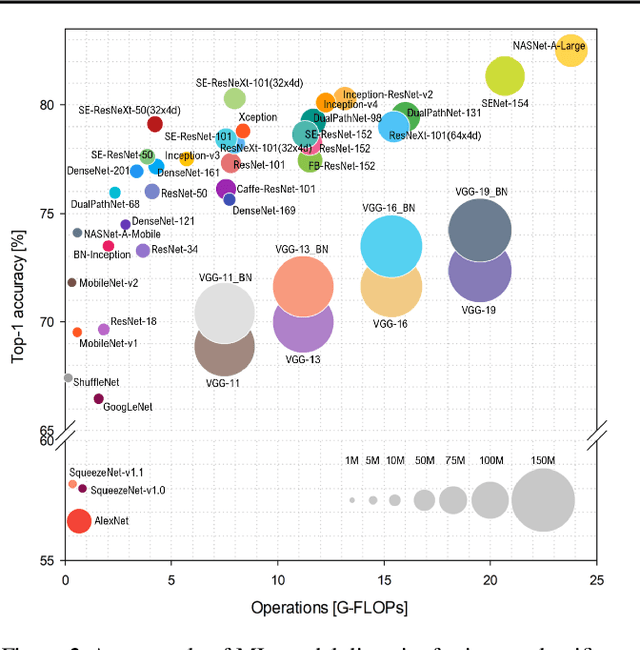
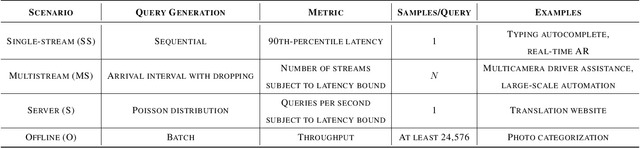
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
MLPerf Training Benchmark
Oct 30, 2019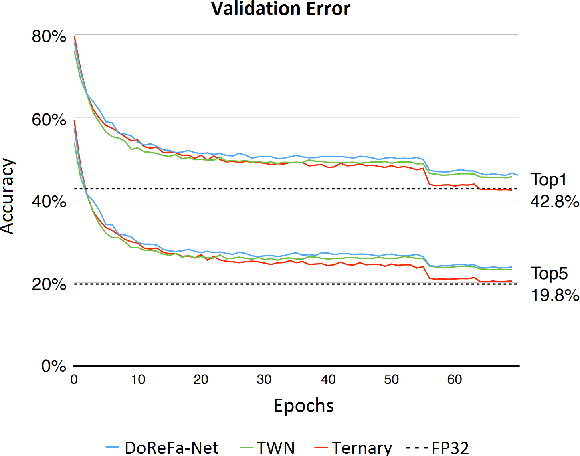
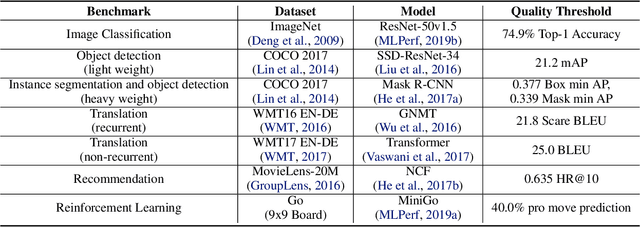
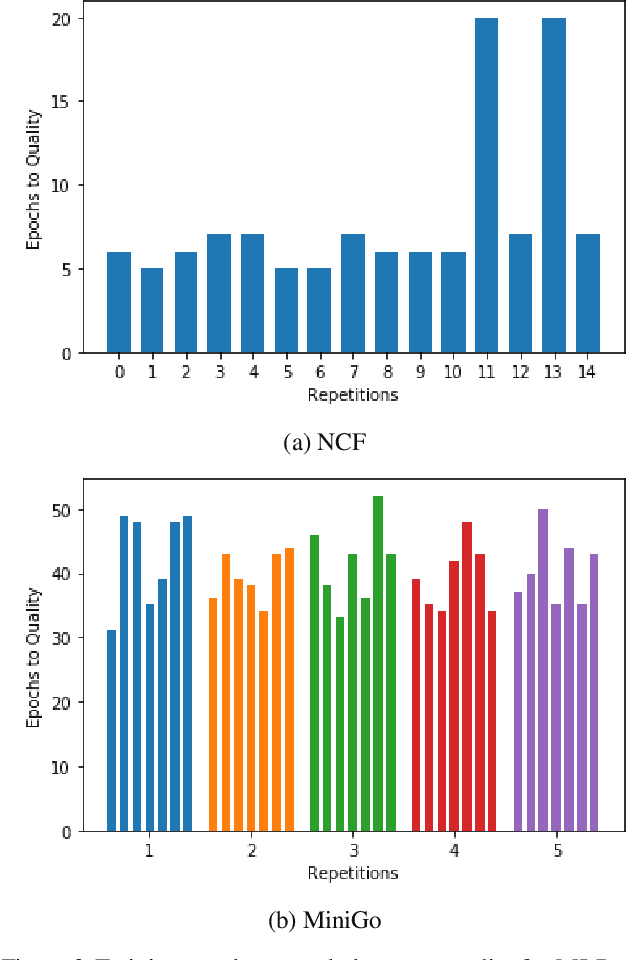
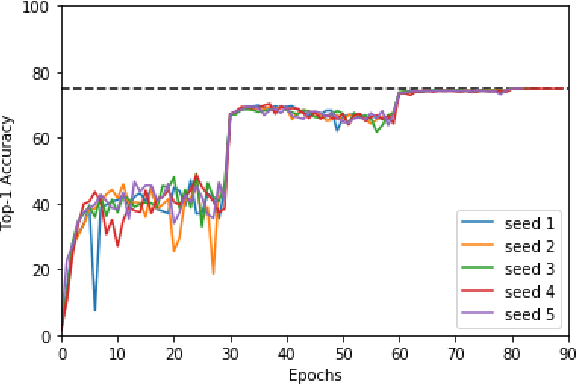
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.